3.5. Task Graph 与数据切分#
章节 3.2 最后对 Dask DataFrame 的 Task Graph 进行了可视化。本节介绍 Dask 的 Task Graph 和数据切分机制。
Task Graph#
和很多大数据计算框架一样,Dask 的计算图是有向无环图(Directed Acyclic Graph,DAG),Dask 称之为 Task Graph,可以通过 .visualize() 方法将 Task Graph 可视化出来。Task Graph 的本质是将众多小的计算任务(Task)组织起来,每个 Task 在单个 Worker 上执行计算。
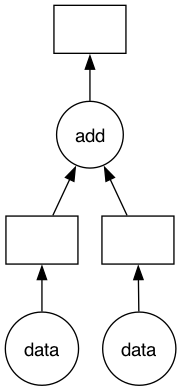
比如下面这个例子,有两类Task:data(i) 接收输入数据;add(x, y) 对两个输入 x 和 y 做加法。
import dask.delayed as delayed
def data(i):
return i
def add(x, y):
return x + y
x = delayed(data)(1)
y = delayed(data)(2)
z = delayed(add)(x, y)
z.visualize(filename='../img/ch-dask/visualize.svg')
z = z.compute()
print(z)
3
在这个例子中,Dask Task Graph 一共有 3 个 Task,实现了数据输入和加法计算。Dask 的设计思想是将复杂的并行计算切分成 Task,每个 Task 是一个 Python 函数。.visualize() 可视化的 Task Graph 中,圆圈是函数,方框是数据占位符。Dask Scheduler 会生成 Task Graph,并将 Task Graph 中的各个计算任务分发到 Dask Worker 上。
值得注意的是,在将多个 Task 组合在一起时,我们使用了 dask.delayed,dask.delayed 是一个偏底层的接口,可以允许用户手动构建计算图。如果用户需要自定义某些任务,就可以使用 dask.delayed 这个装饰器,比如这样:
@dask.delayed
def f(x):
x = x + 1
return x
应该使用:dask.delayed(f)(x, y),而非 dask.delayed(f(x, y)),因为 dask.delayed 修饰的是 Python 函数,而不是函数的输出结果。经过 dask.delayed 修饰的 Python 函数将构成 Task Graph 的一个节点,Dask 并没有创造新的计算引擎,而是通过 Task Graph 的方式将多个 Task 组织起来。Dask 所提供的各类复杂的功能都是基于此实现的。
数据切分#
Dask 将大数据切分成很多个小数据,Dask Array 将切分的小数据称为块(Chunk);Dask DataFrame 将切分的小数据称为分区(Partition)。虽然 Chunk 和 Partition 名词不同,但本质上都是数据的切分。
下面的例子模拟了这样的计算:一个 \(10 \times 10\) 矩阵切分为 4 个 \(5 \times 5\) 矩阵。
import dask.array as da
x = da.ones((10, 10), chunks=(5, 5))
y = x + x.T
y
|
||||||||||||||||
经过了数据切分后,共有 4 个 Chunk,Dask 对这 4 个 Chunk 分配了索引 Index,分别为:(0, 0)、(0, 1)、(1, 0)、(1, 1)。每个 Chunk 调用 NumPy 进行计算,必要时,还需要对多个 Chunk 进行聚合操作。下图给出了这个矩阵运算的 Task Graph。
y.visualize(filename='../img/ch-dask/transpose.svg')

在这个 Task Graph 中,圆圈是计算函数,比如 ones_like 代表 NumPy 的 np.ones_like() 方法,transpose 代表 NumPy 的 np.transpose() 方法;方块是数据占位符,表示经过了前一步计算得到的 NumPy 数据块。
数据切分粒度#
数据切分的粒度会影响 Task Graph:
如果每个数据块很小,那么 Task Graph 将会很大
如果每个数据块很大,那么 Task Graph 将会很小
过大或者过小的数据块都不是最优解。
数据块过小#
如果数据块过小,那么生成的 Task Graph 很大。据统计,Dask Scheduler 协调分发 Task Graph 中的一个计算任务平均需要 1 毫秒,如果 Task Graph 很大,Dask 将花费大量时间用在计算资源协调与分发上。
如果用一个比喻的话,Dask Scheduler 是包工头,Dask Worker 是建筑工人。现在要用很多块砖砌一堵墙,建筑工人将砖块搬到墙上,如果包工头在布置任务时,让每个建筑工人一次只搬一块砖,大量时间都花在了来回搬运上,实际上没有充分利用建筑工人的能力,而且包工头疲于指挥各个建筑工人。对于数据块过小的情况,一方面,Dask Worker 工作欠饱和;另一方面,Dask Scheduler 分发任务的负载也很重。这种场景下,Dask 会生成一个很大的 Task Graph,Dask 输出的日志中通常会带有一些提示,告知用户 Task Graph 过大,影响性能,需要用户优化数据切分方式。
数据块过大#
数据块过大,则 Dask Worker 很容易内存耗尽(Out of Memory,OOM),因为所切分的数据块无法被单个 Dask Worker 所处理。Dask 遇到 OOM 时,会将部分数据卸载到(Spill)硬盘,如果 Spill 之后仍无法完成计算,Dask Worker 进程可能被重启,甚至反复重启。
迭代式算法#
迭代式算法通常会使用循环,循环的当前迭代依赖之前迭代的数据。Dask 的 Task Graph 对于这类迭代式算法处理得并不好,每个数据依赖都会在 Task Graph 中增加有向边,进而会使得 Task Graph 非常庞大,导致执行效率很低。比如,很多机器学习算法、SQL JOIN 都是基于循环的迭代式算法,用户需要对这些操作有心理准备。
设置正确的数据块大小#
总之,在做数据块切分时,不应过大,也不应过小。Dask 没有一个简单通用的设置原则,需要开发者根据自身数据的情况和 Dask 的仪表盘或日志来不断调整。
仪表盘#
如 图 3.4 所示,Dask 仪表盘提供了计算任务运行时信息,用户可以根据仪表盘信息来调整数据分块。
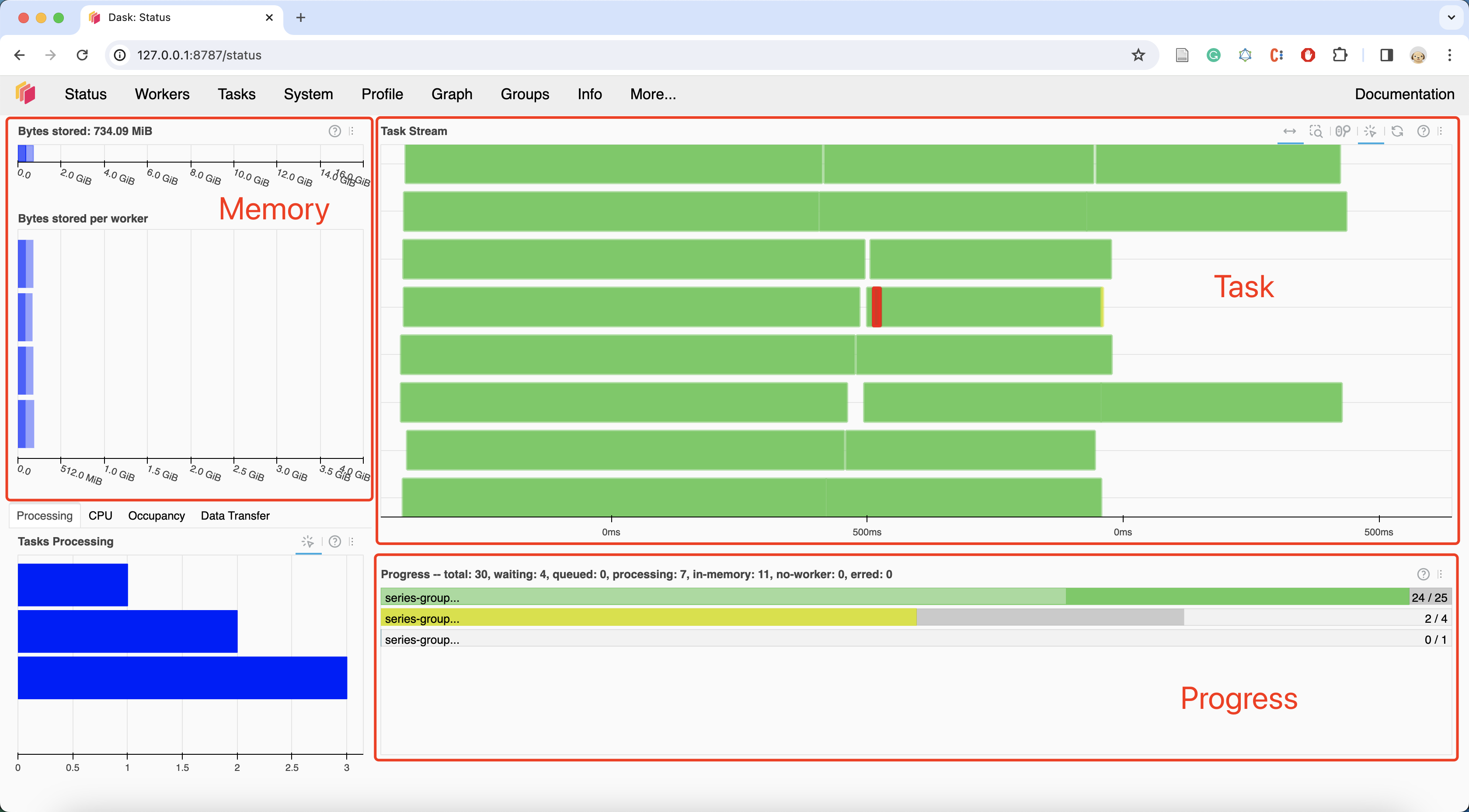
图 3.4 Dask 仪表盘#
我们需要关注 Task Stream 栏,应该避免大量的空白或大量的红色。空白表示 Dask Worker 上没有任何任务,红色表示 Dask Worker 之间进行大量的数据交换。
图 3.5 和 图 3.6 是一个对比,两张图使用代码相同(章节 4.1 中的例子),但是使用的数据块大小不同。图 3.6 中的数据块过小,Task Graph 过大,出现了大量的红色,时间没有用在计算上,而是浪费在数据交换等其他事情上。
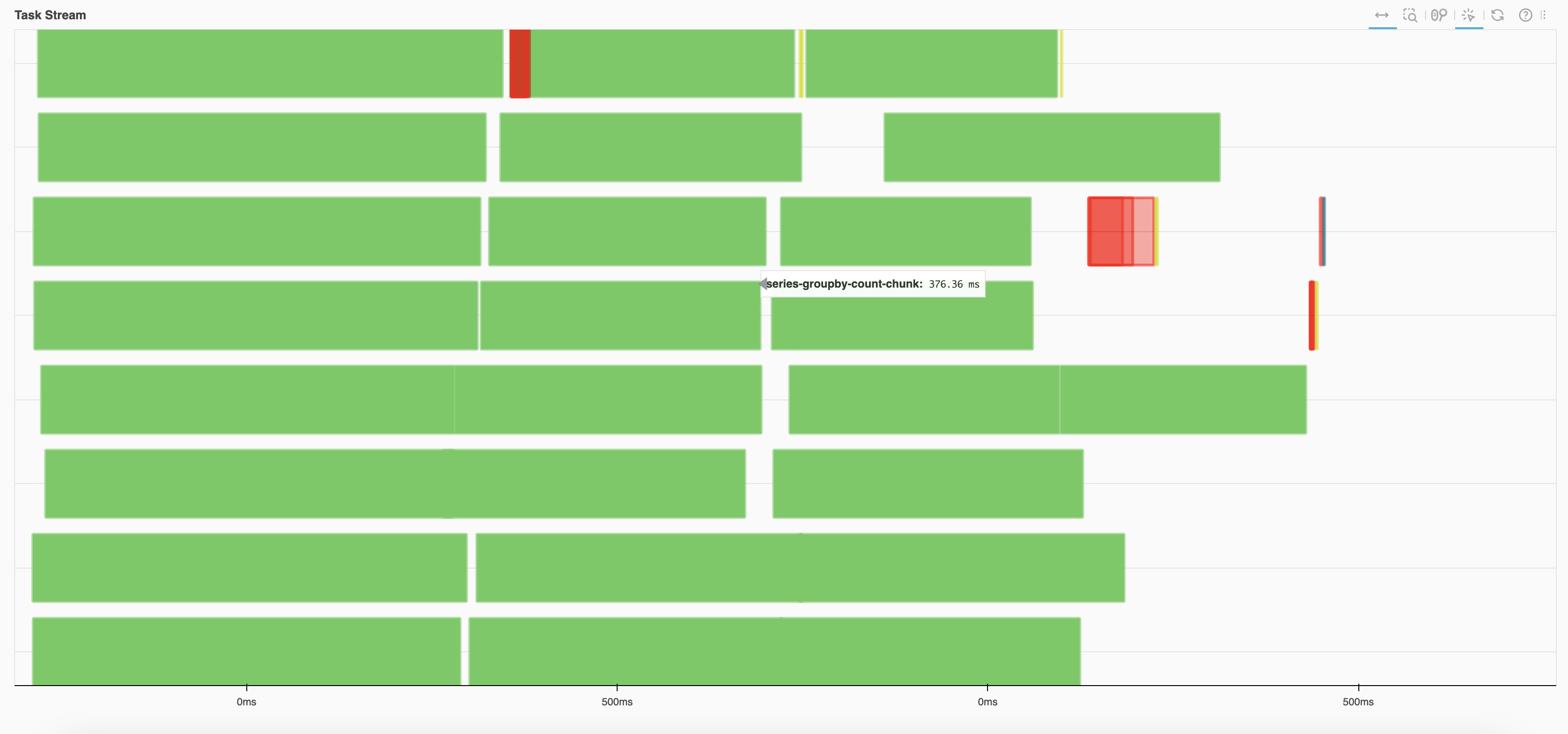
图 3.5 正常的 Task Stream#
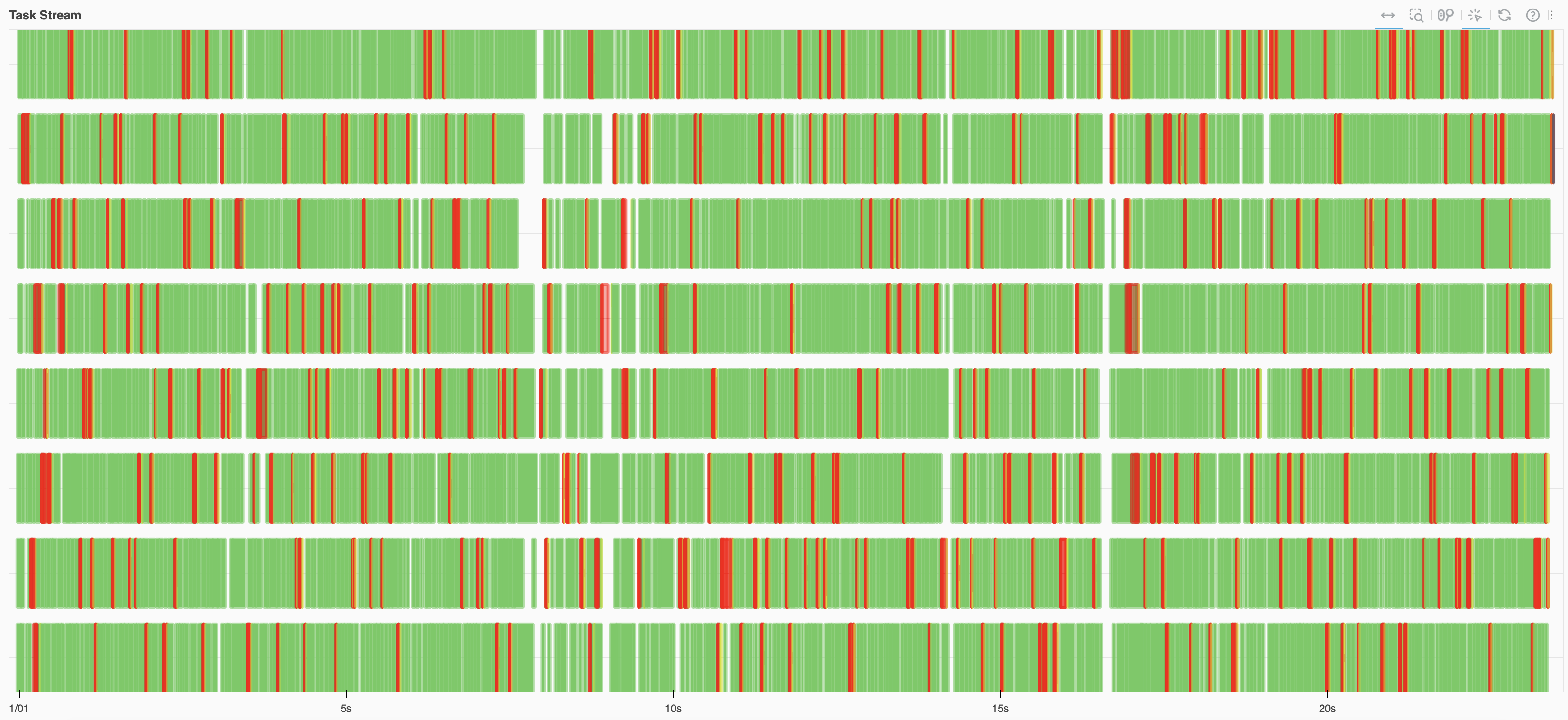
图 3.6 每个 Partition 过小,导致 Task Graph 过大,Task 切分粒度过细,时间没有用在计算上,而是浪费在数据交换等其他事情上#
内存方面,尽量不要出现橙色、灰色或者红色,出现灰色或红色时说明数据切分得太大,超出了 Dask Worker 的内存范围。图 3.7 展示了内存使用状态变化情况。
|
■
|
内存数据在正常范围内 |
|
■
|
内存数据接近卸载的阈值 |
|
■
|
某个 Dask Worker 暂停 |
|
■
|
内存数据卸载到硬盘上 |
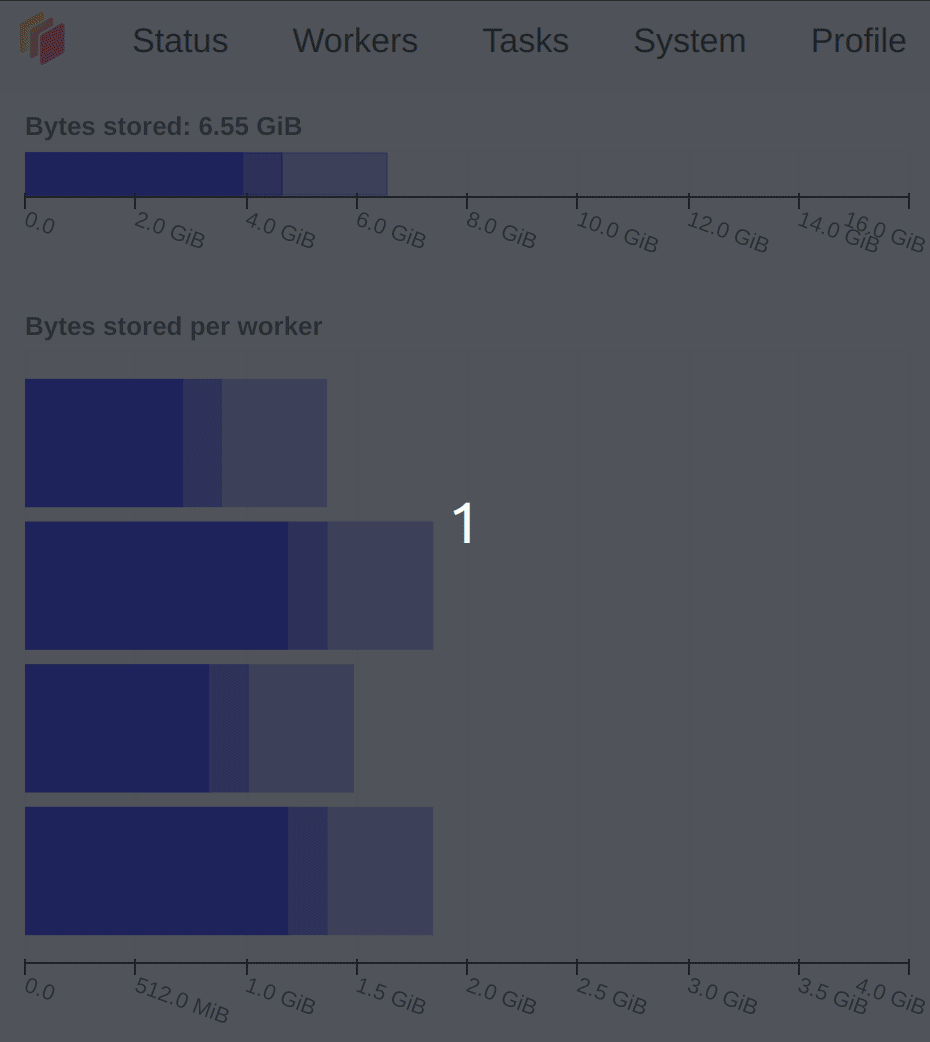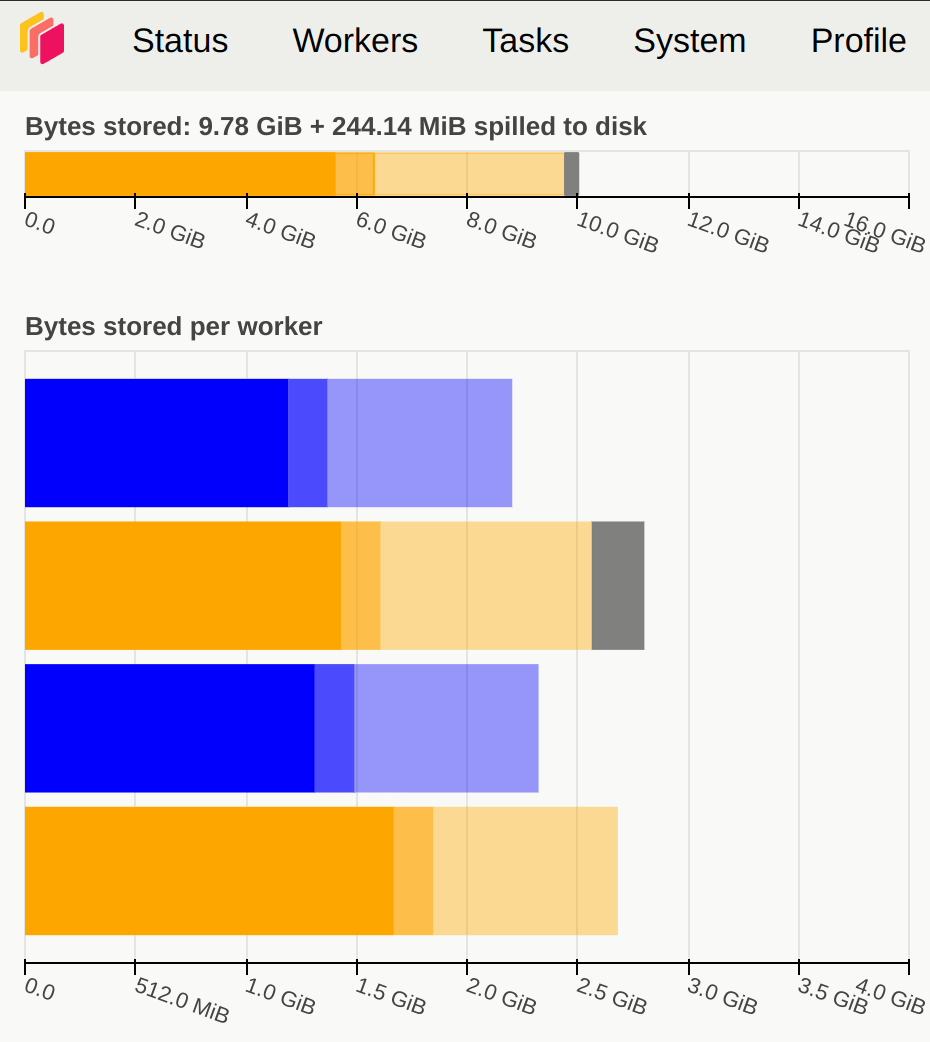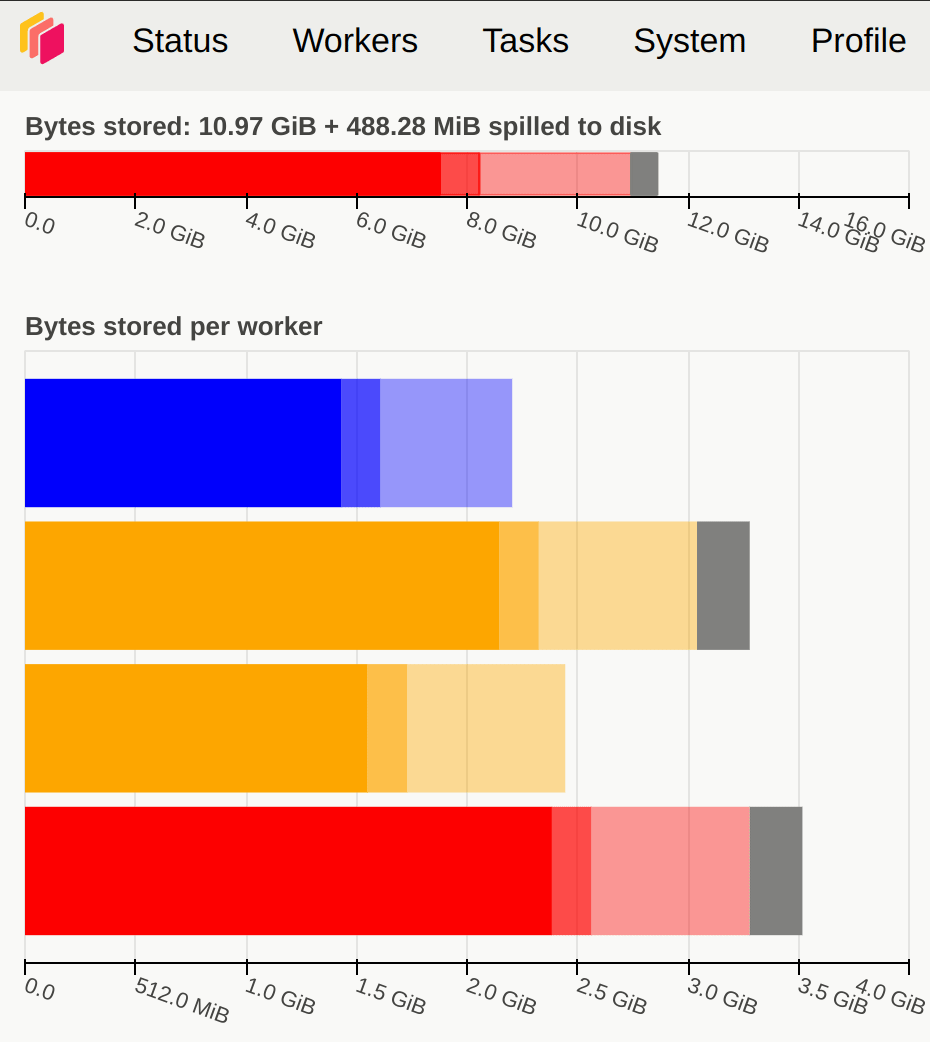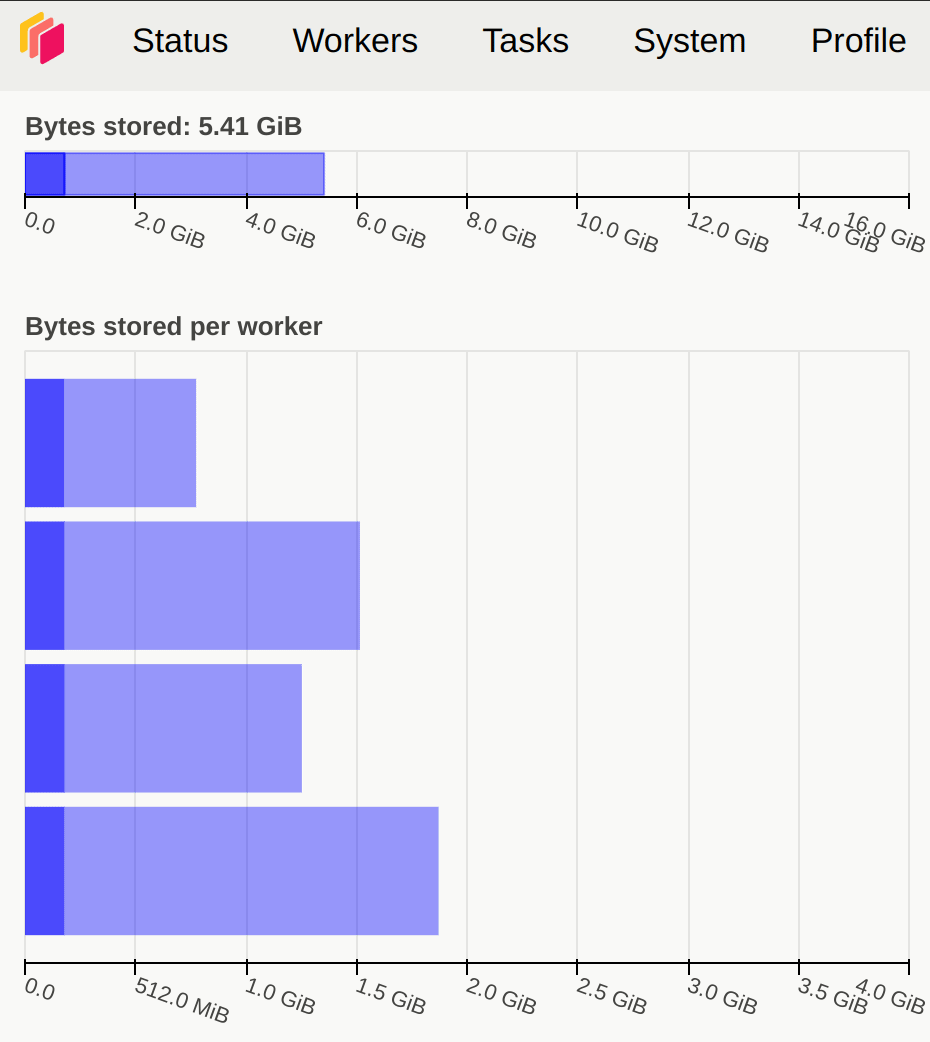
图 3.7 Dask 仪表盘展示了内存使用变化情况#
设置数据块大小#
Dask Array 和 Dask DataFrame 都提供了设置数据块的方式。
可以在初始化时就设定每个数据块的大小,比如 x = da.ones((10, 10), chunks=(5, 5)),chunks 参数用来设置每个数据块大小。也可以在程序运行过程中调整,比如 Dask Array 的 rechunk() 和 Dask DataFrame 的 repartition()。Dask Array 的 rechunk(chunks=...) 在程序运行过程中调整数据块大小,chunks 参数可以是 int 表示切分成多少个数据块,也可以是 (5, 10, 20) 这样的 tuple,表示单个矩阵的维度大小;Dask DataFrame 的 repartition(npartitions=...) 将数据切分成多少个 Partition。